Open-Sourced RAG Pipeline: Revolutionizing Document Processing with Retrieval-Augmented Generation
Introduction
In the rapidly evolving landscape of Natural Language Processing (NLP), Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for enhancing language models' capabilities. This article introduces an open-sourced RAG pipeline, a comprehensive solution designed to transform document processing workflows across various industries.
What is RAG?
Retrieval-Augmented Generation combines the power of large language models with external knowledge retrieval. Unlike traditional language models that rely solely on their pre-trained knowledge, RAG systems can access and incorporate up-to-date information from external sources, making them more accurate and contextually aware.
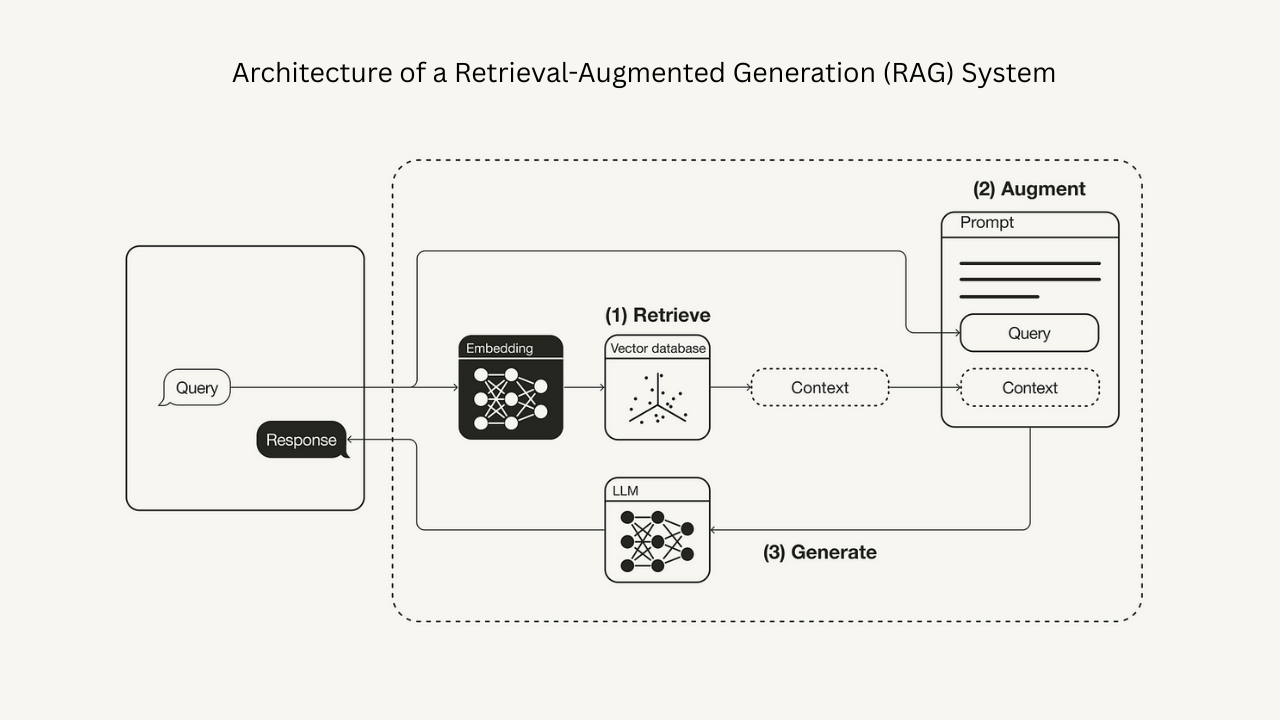
Understanding the RAG Pipeline
The RAG pipeline consists of several key processes that work together to provide accurate and contextually relevant responses:
1. Document Processing and Chunking
Chunking is the process of breaking down large documents into smaller, manageable pieces while preserving their semantic meaning. The pipeline implements several strategies:
- Semantic Chunking: Text is split based on semantic boundaries (paragraphs, sections) rather than fixed character counts
- Overlap Strategy: Context is maintained by allowing chunks to overlap slightly, preventing information loss at boundaries
- Smart Chunking: LangChain's text splitters are used to maintain document structure and relationships
2. Vector Embedding and Storage
Once documents are chunked, they are converted into vector embeddings:
- Embedding Generation: State-of-the-art embedding models convert text into high-dimensional vectors
- Vector Storage: These embeddings are stored in ChromaDB with metadata for efficient retrieval
- Upserting: A combination of "update" and "insert" operations that:
- Update existing vectors if the document has changed
- Insert new vectors for new content
- Maintain document versioning and history
3. Retrieval Process
The retrieval process is optimized for both speed and relevance:
- Query Processing:
- User queries are converted into vector embeddings
- Query expansion techniques are applied for better context understanding
- Complex queries with multiple components are handled
- Similarity Search:
- Cosine similarity is used to find the most relevant document chunks
- Approximate nearest neighbor (ANN) search is implemented for efficiency
- Filtering is applied based on metadata and document types
- Re-ranking:
- Retrieved chunks are re-ranked based on relevance to the query
- Document freshness and importance are considered
- Diversity sampling is applied to avoid redundant information
4. Generation Process
The final step combines retrieved information with language model generation:
- Context Integration:
- Relevant chunks are combined into a coherent context
- Proper context window limits are maintained
- Multiple document sources are handled
- Prompt Engineering:
- The prompt is structured to include retrieved context
- System messages guide model behavior
- Few-shot examples are implemented for better performance
- Response Generation:
- The language model generates responses
- Responses are grounded in retrieved information
- Coherence and relevance are maintained
Key Components
- Document Processing Layer: Multiple document formats including PDFs, images, and text files are handled
- Vector Storage System: ChromaDB is used for efficient vector storage and retrieval
- Language Model Integration: Multiple state-of-the-art models are supported
- Text Processing Pipeline: LangChain powers sophisticated text handling
Technical Implementation
The pipeline is built using several key technologies:
- Python 3.8+ as the primary programming language
- Transformers and AutoGPTQ for language model inference
- ChromaDB for vector storage and retrieval
- LangChain for text processing and chunking
Supported Models
The pipeline supports several state-of-the-art language models:
- OpenChat 3.5
- Mixtral 8x7B
- Vicuna 13B v1.5 16K
- Zephyr 7B Beta
System Architecture
The pipeline consists of three main components:
- Document Processing:
- OCR capabilities for image processing
- PDF text extraction and processing
- Text file handling
- Vector Storage:
- ChromaDB integration
- Cosine similarity-based retrieval
- Metadata management
- Model Integration:
- Support for multiple model architectures
- Optimized inference using AutoGPTQ
- Context window management
Usage Example
Here's how to use the pipeline:
python rag_pipeline.py -s document.pdf -q "What are the key responsibilities mentioned in this document?"Technical Requirements
The system requires:
- Minimum 16GB RAM (32GB recommended)
- CUDA-compatible GPU for model inference
- Sufficient disk space for model storage
Future Developments
Active development is focused on several enhancements:
- Support for additional document formats
- Improved retrieval algorithms
- Enhanced model fine-tuning capabilities
- Better memory management for large documents
Conclusion
This open-sourced RAG pipeline represents a significant step forward in document processing and information retrieval. By combining state-of-the-art language models with efficient vector storage and retrieval mechanisms, it provides a powerful tool that can transform how organizations process and extract insights from their documents.
Contributions to this project are welcome. Whether you're interested in improving the core functionality, adding new features, or optimizing performance, your participation is encouraged.
Back to Blog